Get Started
Now we will check how to install stable version of Apache Hadoop on a Laptop running Linux Mint 15 but will work on all Debian based systems including Ubuntu. To start we need to acquire hadoop package and get java installed, to install java, if not already installed follow my install java post. to check which versions of java are supported with hadoop check Hadoop Java Versions. Next step is to acquire hadoop which could be downloaded @ hadoop webpage. we opted for hadoop-2.2.0 in our blog.Apache Hadoop NextGen MapReduce (YARN)
MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker, resource management and job scheduling/monitoring, into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
The ResourceManager and per-node slave, the NodeManager (NM), form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
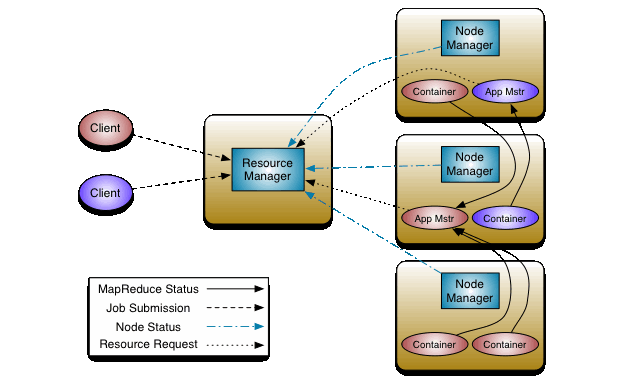
The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application. Also, it offers no guarantees about restarting failed tasks either due to application failure or hardware failures. The Scheduler performs its scheduling function based the resource requirements of the applications; it does so based on the abstract notion of a resource Container which incorporates elements such as memory, cpu, disk, network etc. In the first version, only memory is supported.
The Scheduler has a pluggable policy plug-in, which is responsible for partitioning the cluster resources among the various queues, applications etc. The current Map-Reduce schedulers such as the CapacityScheduler and the FairScheduler would be some examples of the plug-in.
The CapacityScheduler supports hierarchical queues to allow for more predictable sharing of cluster resources
The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure.
The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.
Apache Hadoop2.0 Installation
Create Dedicated Hadoop User
$ sudo addgroup hadoop$ sudo adduser --ingroup hadoop hdpuser
Give user sudo rights
$ sudo nano /etc/sudoersadd this to end of file
hdpuser ALL=(ALL:ALL) ALL
Configuring Secure Shell (SSH)
Communication between master and slave nodes uses SSH, to ensure we have SSH server installedand running SSH deamon.
Installed server with provided command:
$ sudo apt-get install openssh-serverYou can check status of server use this command
$ /etc/init.d/ssh statusTo start ssh server use:
$ /etc/init.d/ssh startNow ssh server is running, we need to set local ssh connection with password. To enable passphraseless ssh use
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
to check ssh
$ ssh localhost$ exit
Disabling IPv6
We need to make sure IPv6 is disabled, it is best to disable IPv6 as all Hadoop communication between nodes is IPv4-based.For this, first access the file /etc/sysctl.conf
$ sudo nano /etc/sysctl.confadd following lines to end
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
Save and exit
Reload sysctl for changes to take effect
$ sudo sysctl -p /etc/sysctl.confIf the following command returns 1 (after reboot), it means IPv6 is disabled.
$ cat /proc/sys/net/ipv6/conf/all/disable_ipv6Install Hadoop
Download Version 2.2.0 (Stable Version)Make Hadoop installation directory
$ sudo mkdir -p /usr/hadoopCopy Hadoop installer to installation directory
$ sudo cp -r ~/Downloads/hadoop-2.2.0.tar.gz /usr/hadoopExtract Hadoop installer
$ cd /usr/hadoop$ sudo tar xvzf hadoop-2.2.0.tar.gz
Rename it to hadoop
$ sudo mv hadoop-2.2.0 hadoopChange owner to hdpuser for this folder
$ sudo chown -R hdpuser:hadoop hadoopUpdate .bashrc with Hadoop-related environment variables
$ sudo nano ~/.bashrcAdd following lines at the end:
# Set Hadoop-related environment variables
export HADOOP_HOME=/usr/hadoop/hadoop
export HADOOP_PREFIX=/usr/hadoop/hadoop
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# Native Path
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
#Java path
# Import if you have installed java from apt-get
# use /usr/local/java/jdk1.7.0_51 (1.7.0_51 installed version) instead of /usr/
export JAVA_HOME='/usr/'
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin:$JAVA_PATH/bin:$HADOOP_HOME/sbin
Save & Exit
Reload bashrc
$ source ~/.bashrcUpdate JAVA_HOME in hadoop-env.sh
$ cd /usr/hadoop/hadoop$ sudo vi etc/hadoop/hadoop-env.sh
Add the line:
export JAVA_HOME=/usr/
or if Java is Installed Manually
export JAVA_HOME=/usr/local/java/jdk1.7.0_51
Save and exit
Create a Directory to hold Hadoop’s Temporary Files:
$ sudo mkdir -p /usr/hadoop/tmpProvide hdpuser the rights to this directory
$ sudo chown hdpuser:hadoop /usr/hadoop/tmpHadoop Configurations
Modify core-site.xml – Core Configuration
$ sudo nano etc/hadoop/core-site.xml
Add the following lines between configuration tags
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>Hadoop's temporary directory</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
</property>
Add the following lines between configuration tags
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>Hadoop's temporary directory</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
</property>
Modify mapred-site.xml – MapReduce configuration
$ sudo cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
$ sudo nano etc/hadoop/mapred-site.xml
Add the following lines between configuration tags
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The URI is used to monitor the status of MapReduce tasks</description>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
$ sudo nano etc/hadoop/mapred-site.xml
Add the following lines between configuration tags
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The URI is used to monitor the status of MapReduce tasks</description>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
Modify yarn-site.xml – YARN
$ sudo nano etc/hadoop/yarn-site.xmlAdd following lines between configuration tags:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
Modify hdfs-site.xml – File Replication
$ sudo nano etc/hadoop/hdfs-site.xml
Add following lines between configuration tags and check file path:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop/yarn_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop/yarn_data/hdfs/datanode</value>
</property>
Add following lines between configuration tags and check file path:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop/yarn_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop/yarn_data/hdfs/datanode</value>
</property>
Initializing the Single-Node Cluster
Formatting the Name Node:
While setting up the cluster for the first time, we need to initially format the Name Node in HDFS.
$ bin/hadoop namenode -format
$ bin/hadoop namenode -format
Starting all daemons:
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
4829 ResourceManager
4643 NameNode
4983 NodeManager
5224 JobHistoryServer
4730 DataNode
7918 Jps
You should now be able to browse the nameNode in your browser (after a short delay for startup) by browsing to the following URLs:
nameNode: http://localhost:50070/
$ sbin/hadoop-daemon.sh start datanode
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
Check all daemon processes:
$ jps4829 ResourceManager
4643 NameNode
4983 NodeManager
5224 JobHistoryServer
4730 DataNode
7918 Jps
You should now be able to browse the nameNode in your browser (after a short delay for startup) by browsing to the following URLs:
nameNode: http://localhost:50070/
Stoping all daemons:
$ sbin/hadoop-daemon.sh stop namenode
$ sbin/hadoop-daemon.sh stop datanode
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/mr-jobhistory-daemon.sh stop historyserver
$ sbin/hadoop-daemon.sh stop datanode
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/mr-jobhistory-daemon.sh stop historyserver
Now run examples. looking for examples to run without changing your style of code, am going run Python MapReduce on New Version of Hadoop wait for post.
No comments:
Post a Comment