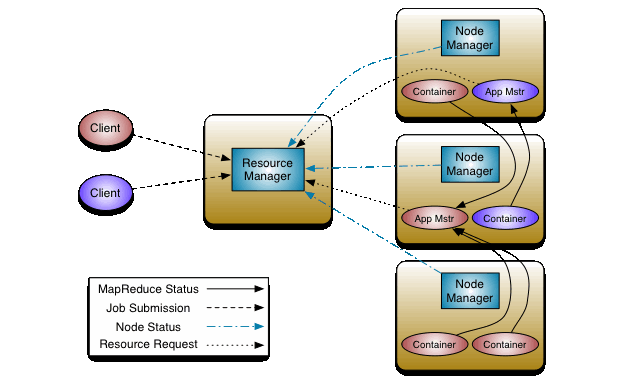
Overview
Even though the Hadoop framework is written in Java, but we can use other languages like python and C++, to write MapReduce for Hadoop. However, Hadoop’s documentation suggest that your must translate your code to java jar file using jython. which is not very convenient and can even be problematic if you depend on Python features not provided by Jython.Example
We will write simple WordCount MapReduce program using pure python. input is text files and output is file with words and thier count. you can use other languages like perl.Prerequisites
You should have hadoop cluster running if still not have cluster ready Try this to start with single node cluster.MapReduce
Idea behind python code is that we will use hadoop streaming API to transfer data/Result between our Map and Reduce code using STDIN(sys.stdin)/ STDOUT(sys.stdout). We will use STDIN to read datafrom input and print output to STDOUT.
Mapper
Mapper maps input key/value pairs to a set of intermediate
key/value pairs.
Maps are the individual tasks that transform input records into
intermediate records. The transformed intermediate records do not need
to be of the same type as the input records. A given input pair may
map to zero or many output pairs.
The Hadoop MapReduce framework spawns one map task for each
InputSplit generated by the InputFormat for
the job.
Output pairs do not need to be of the same types as input pairs. A
given input pair may map to zero or many output pairs. All intermediate values associated with a given output key are
subsequently grouped by the framework, and passed to the
Reducer(s) to determine the final output. The Mapper outputs are sorted and then
partitioned per Reducer. The total number of partitions is
the same as the number of reduce tasks for the job.
How Many Maps?
The number of maps is usually driven by the total size of the
inputs, that is, the total number of blocks of the input files.
The right level of parallelism for maps seems to be around 10-100
maps per-node, although it has been set up to 300 maps for very
cpu-light map tasks. Task setup takes awhile, so it is best if the
maps take at least a minute to execute.
Thus, if you expect 10TB of input data and have a blocksize of
128MB, you'll end up with 82,000 maps, unless
setNumMapTasks(int) (which only provides a hint to the framework)
is used to set it even higher.
Reducer
Reducer reduces a set of intermediate values which share a key to
a smaller set of values. The number of reduces for the job is set by the user
via
JobConf.setNumReduceTasks(int). Reducer has 3 primary phases: shuffle, sort and reduce.
Shuffle
Input to the Reducer is the sorted output of the
mappers. In this phase the framework fetches the relevant partition
of the output of all the mappers, via HTTP.
Sort
The framework groups Reducer inputs by keys (since
different mappers may have output the same key) in this stage.
The shuffle and sort phases occur simultaneously; while
map-outputs are being fetched they are merged.
Reduce
In this phase the
reduce
method is called for each <key, (list of values)>
pair in the grouped inputs. The output of the reduce task is typically written to the File-system. Applications can use the Reporter to report
progress, set application-level status messages and update
Counters, or just indicate that they are alive.
*The output of the Reducer is not sorted.
How Many Reduces?
The right number of reduces seems to be 0.95 or
1.75 multiplied by (<no. of nodes> *
mapred.tasktracker.reduce.tasks.maximum).
With 0.95 all of the reduces can launch immediately
and start transferring map outputs as the maps finish. With
1.75 the faster nodes will finish their first round of
reduces and launch a second wave of reduces doing a much better job
of load balancing.
Increasing the number of reduces increases the framework overhead,
but increases load balancing and lowers the cost of failures.
The scaling factors above are slightly less than whole numbers to
reserve a few reduce slots in the framework for speculative-tasks and
failed tasks.
Reducer NONE
It is legal to set the number of reduce-tasks to zero if no reduction is desired.In this case the outputs of the map-tasks go directly to the File-system, into the output path. The framework does not sort the map-outputs before writing them out to the File-system.
Sample Code:
mapper.py
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)
reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
Running Hadoop's Job
Download Example Data to home directory like /home/elite/Downloads/examples/Book1
Book2
Book3
Start Cluster
$ sbin/hadoop-daemon.sh start namenode$ sbin/hadoop-daemon.sh start datanode
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
Copy Data from Local to dfs File System
$ bin/hadoop dfs -mkdir /wordscount
$ bin/hadoop dfs -copyFromLocal /home/hdpuser/gutenberg/ /wordscount/
Here we have created directory in hadoop file system named wordcount and moved our local directory containing our test data to hadoop hdfs. We can check if files have been copied properly to hadoop directory by listing its content as presented below.
Check files on dfs
$ bin/hadoop dfs -ls /wordscount/gutenberg
Run MapReduce Job
I have both mapper.py and reducer.py and /home/hdpuser/ here is command to run job.$ bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar -file /home/hdpuser/mapper.py -mapper /home/hdpuser/mapper.py -file /home/hdpuser/reducer.py -reducer /home/hdpuser/reducer.py -input /wordscount/gutenberg/* -output /wordscount/wc.out
You Can check status from terminal or web page http://elite-pc:19888/jobhistory This will provide you extensive details about executed job.
* Note we are providing mapper.py and reducer.py files with our local path, you might need to change this path if you have placed scripts to some other locations.
* Be careful to provide correct jar file for "hadoop-streaming-X.X.X.jar" we have used "hadoop-streaming-2.2.0.jar" since we are using hadoop 2.2.0, if you are using Hadoop 2.6.0 then you should use hadoop-streaming-2.6.0.jar etc.
Check Result
Browse this url and check for created files, this url is fetched from http://localhost:50070 to access file system.http://localhost:50075/browseDirectory.jsp?namenodeInfoPort=50070&dir=/&nnaddr=127.0.0.1:54310
Stop running cluster
$ sbin/hadoop-daemon.sh stop namenode$ sbin/hadoop-daemon.sh stop datanode
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/mr-jobhistory-daemon.sh stop historyserver